树形结构的数据库表Schema设计
程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化。然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将Tree存入DBMS,设计合适的Schema及其对应的CRUD算法是实现关系型数据库中存储树形结构的关键。
理想中树形结构应该具备如下特征:数据存储冗余度小、直观性强;检索遍历过程简单高效;节点增删改查CRUD操作高效。依据Gijs Van Tulder写的《Storing Hierarchical Data in a Database》整理了一下,本文将介绍三种树形结构的Schema设计方案:
- The Adjacency List Model(“邻接列表模型”或“递归方法”)
- Route Path(路径法)
- Modified Preorder Tree Traversal(预排序遍历树算法,基于节点左右值编码的改进方案)
树模型实例
以食品作为演示数据,通过类别、颜色、品种进行分类,树结构如下:
Food
|---Fruit
| |---Red
| | +---Cherry
| +---Yellow
| +---Banana
|---Meat
|---Beef
+---Pork
The Adjacency List Model(“邻接列表模型”或“递归方法”)
这种模式我们经常用到,很多的教程和书中也介绍过。我们通过给每个节点增加一个属性 parentID 来表示这个节点的父节点从而将整个树状结构通过平面的表描述出来。这种方案的Tree表结构通常设计为:{ID,parentID},上述数据可以描述为如下图所示:
+----+--------+----------+
| ID | tName | parentID |
+----+--------+----------+
| 1 | Food | 0 |
| 2 | Fruit | 1 |
| 3 | Red | 2 |
| 4 | Yellow | 2 |
| 5 | Cherry | 3 |
| 6 | Banana | 4 |
| 7 | Meat | 1 |
| 8 | Beef | 7 |
| 9 | Pork | 7 |
+----+--------+----------+
parentID 对应 ID,parentID=0时表示其无父级
这种模式适用需要对树末端节点(叶子)进行增加、删除、移动的操作(删除、移动最好先行判断是否末端节点),也适用于对子树的移动。但读取某个节点的子孙节点数、同级节点、节点所在层级、节点到根节点的路径、删除子树将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。当然,这种方案并非没有用武之地,在树规模相对较小的情况下,我们可以借助于缓存机制来做优化,将树的信息载入内存进行处理,避免直接对数据库IO操作的性能开销,不过这也只能解决单纯对树本身的操作。
Route Path(路径法)
通过记录每个节点到根节点的路径的方法整个树状结构通过平面的表描述出来。这种方案的Tree表结构通常设计为:{ID,pathnode},上述数据可以描述为如下图所示:
+----+--------+-----------+
| ID | tName | pathNode |
+----+--------+-----------+
| 1 | Food | ,1, |
| 2 | Fruit | ,1,2, |
| 3 | Red | ,1,2,3, |
| 4 | Yellow | ,1,2,4, |
| 5 | Cherry | ,1,2,3,5, |
| 6 | Banana | ,1,2,4,6, |
| 7 | Meat | ,1,7, |
| 8 | Beef | ,1,7,8, |
| 9 | Pork | ,1,7,9, |
+----+--------+-----------+
pathNode 以“,”开始结束,方便Like查询
这种模式解决了第一种模式的不足,但有两点美中不足: * 增加节点时需要先获取到新节点的ID才能得到完整的路径 * 所有操作都是基于Like或者数组进行的
Modified Preorder Tree Traversal(预排序遍历树算法,基于节点左右值编码的改进方案)
在基于数据库的一般应用中,查询的需求总要大于删除和修改,我们希望尽量减少对数据库的查询次数,最好每个活动只有一个查询来提高程序的效率,现在让我们看看另外一种树结构的存储方法:
+----+--------+------+------+
| ID | tName | lft | rgt |
+----+--------+------+------+
| 1 | Food | 1 | 18 |
| 2 | Fruit | 2 | 11 |
| 3 | Red | 3 | 6 |
| 4 | Yellow | 7 | 10 |
| 5 | Cherry | 4 | 5 |
| 6 | Banana | 8 | 9 |
| 7 | Meat | 12 | 17 |
| 8 | Beef | 13 | 14 |
| 9 | Pork | 15 | 16 |
+----+--------+------+------+
如下图所示。当我们从根节点Food左侧开始,标记为1,并沿前序遍历的方向,依次在遍历的路径上标注数字,最后我们回到了根节点Food,并在右边写上了18。
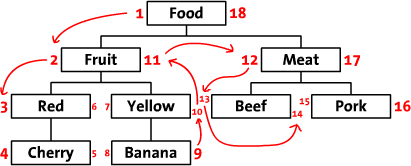
这种左右值编码的设计方案,在对树进行查询遍历时消除了递归,查询条件都是数字的比较,查询的效率不言而喻。但是左右值模式在插入、删除、移动节点或子树时代价较大,将会涉及到表中的多条数据改动。此种方案适合树不经常变动读取量大的场景中使用。
总结
上述三种方案结合再对表结构增加”tLevel”字段(节点层级),对树增删移后进行修复,在对树的需求场景中均能高效率应对。引用《倚天屠龙记》片段作为结尾:
张三丰这套武功由真武大帝座下龟蛇二将而触机创制,是以名之为“真武七截阵”。他当时苦思难解者,总觉顾得东边,西边便有漏洞,同时南边北边,均予敌人可乘之机,后来想到可命七弟于齐施,才破解了这个难题。只是这“真武七截阵”不能由一人施展,总不免遗憾,但转念想道:“这路武功倘若一人能使,岂非单是一人,便足匹敌当世六十四位第一流高手,这念头也未免过于荒诞狂妄了。”不禁哑然失笑。