简约的技术
On Cqun.com
Windows扩容磁盘分区
16年10月08日
进入cmd界面,输入diskpart命名:
C:\Documents and Settings\Administrator>diskpart
Microsoft DiskPart Copyright (C) 1999-2001 Microsoft Corporation.
On computer: HBSCSHARE
DISKPART>
输入list disk,显示磁盘列表
DISKPART> list disk
磁盘 ### 状态 大小 可用 动态 Gpt
-------- ---------- ------- ------- --- ---
磁盘 0 联机 70 GB 10 GB
磁盘 1 联机 100 GB 672 KB *
输入select disk 0,选择磁盘0(我们这次对磁盘0进行扩容)
DISKPART> select disk 0
磁盘 0 现在是所选磁盘。
输入list partition,显示磁盘0的分区列表
DISKPART> list partition
分区 ### 类型 大小 偏移
------------- ---------------- ------- -------
分区 1 主要 20 GB 32 KB
分区 2 扩展的 40 GB 20 GB
分区 3 逻辑 40 GB 20 GB
输入select partition 3,选择分区3
DISKPART> select partition 3
分区 3 现在是所选分区。
输入list partition,看看分区3是否被选中(*标识的为选中)
DISKPART> list partition
分区 ### 类型 大小 偏移
------------- ---------------- ------- -------
分区 1 主要 20 GB 32 KB
分区 2 扩展的 40 GB 20 GB
* 分区 3 逻辑 40 GB 20 GB
输入extend
DISKPART> extend
DiskPart 成功地扩展了卷。
扩容成功了,不需要安装第三方软件,也不需要重启系统。
Asp.Net Core 微信接口配置
16年09月27日
先看代码:
private bool CheckSignature(string token, string signature, string timestamp, string nonce)
{
string[] ArrTmp = { token, timestamp, nonce };
Array.Sort(ArrTmp);
string tmpStr = string.Join("", ArrTmp);
byte[] tmpByte = Encoding.UTF8.GetBytes(tmpStr);
tmpByte = SHA1.Create().ComputeHash(tmpByte);
tmpStr = BitConverter.ToString(tmpByte);
tmpStr = tmpStr.Replace("-", tmpStr).ToLower();
//tmpStr= BitConverter.ToString(SHA1.Create().ComputeHash(Encoding.UTF8.GetBytes(tmpStr))).Replace("-", "").ToLower();
if (tmpStr == signature)
{
return true;
}
else
{
return false;
}
}
这里有两点需要注意地方:
- 编码字符串时要使用Encoding.UTF8
- 编码转换成字符串时用BitConverter.ToString
LINQ to SQL with NOLOCK
16年09月20日
If your project uses LINQ to SQL for your database access, you may want to use NOLOCK to set the isolation level to ReadUncommitted on your Select statements. The problem is that LINQ does not understand query hints. The way this works with LINQ is by running your Select statements under the context of a transaction scope, as follows:
string type = string.Empty;
using (DataContext ctx = new DataContext(ConnectionString))
{
using (var tx = new System.Transactions.TransactionScope(TransactionScopeOption.Required,
new TransactionOptions() { IsolationLevel = IsolationLevel.ReadUncommitted }))
{
var row = (from record in ctx.Log
where record.Id == 99999
select record).FirstOrDefault();
type = row.Type;
}
}
The code here creates a transaction scope and sets the isolation level to ReadUncommitted (NOLOCK). The Select statement runs under the scope of the transaction, and it returns the value from a query. The using clause ensures that both the transactions as well as the data context are disposed once the code goes out of scope.
There is also the preferable option to use Stored Procedures to eliminate the need to use transaction scope. In the Stored Procedure, you have the flexibility to use query hints.
I hope this helps.
Git分支管理策略
16年09月09日
如果你严肃对待编程,就必定会使用”版本管理系统”(Version Control System)。眼下最流行的”版本管理系统”,非Git莫属。
![]()
相比同类软件,Git有很多优点。其中很显著的一点,就是版本的分支(branch)和合并(merge)十分方便。有些传统的版本管理软件,分支操作实际上会生成一份现有代码的物理拷贝,而Git只生成一个指向当前版本(又称”快照”)的指针,因此非常快捷易用。
但是,太方便了也会产生副作用。如果你不加注意,很可能会留下一个枝节蔓生、四处开放的版本库,到处都是分支,完全看不出主干发展的脉络。

Vincent Driessen提出了一个分支管理的策略,我觉得非常值得借鉴。它可以使得版本库的演进保持简洁,主干清晰,各个分支各司其职、井井有条。理论上,这些策略对所有的版本管理系统都适用,Git只是用来举例而已。如果你不熟悉Git,跳过举例部分就可以了。
一、主分支Master
首先,代码库应该有一个、且仅有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。

Git主分支的名字,默认叫做Master。它是自动建立的,版本库初始化以后,默认就是在主分支在进行开发。
二、开发分支Develop
主分支只用来分布重大版本,日常开发应该在另一条分支上完成。我们把开发用的分支,叫做Develop。

这个分支可以用来生成代码的最新隔夜版本(nightly)。如果想正式对外发布,就在Master分支上,对Develop分支进行”合并”(merge)。
Git创建Develop分支的命令:
git checkout -b develop master
将Develop分支发布到Master分支的命令:
git checkout master
git merge --no-ff develop
这里稍微解释一下,上一条命令的–no-ff参数是什么意思。默认情况下,Git执行”快进式合并”(fast-farward merge),会直接将Master分支指向Develop分支。

使用–no-ff参数后,会执行正常合并,在Master分支上生成一个新节点。为了保证版本演进的清晰,我们希望采用这种做法。关于合并的更多解释,请参考Benjamin Sandofsky的《Understanding the Git Workflow》。

三、临时性分支
前面讲到版本库的两条主要分支:Master和Develop。前者用于正式发布,后者用于日常开发。其实,常设分支只需要这两条就够了,不需要其他了。
但是,除了常设分支以外,还有一些临时性分支,用于应对一些特定目的的版本开发。临时性分支主要有三种: * 功能(feature)分支 * 预发布(release)分支 * 修补bug(fixbug)分支
这三种分支都属于临时性需要,使用完以后,应该删除,使得代码库的常设分支始终只有Master和Develop。
四、 功能分支
接下来,一个个来看这三种”临时性分支”。
第一种是功能分支,它是为了开发某种特定功能,从Develop分支上面分出来的。开发完成后,要再并入Develop。

功能分支的名字,可以采用feature-*的形式命名。
创建一个功能分支:
git checkout -b feature-x develop
开发完成后,将功能分支合并到develop分支:
git checkout develop
git merge --no-ff feature-x
删除feature分支:
git branch -d feature-x
## 五、预发布分支
第二种是预发布分支,它是指发布正式版本之前(即合并到Master分支之前),我们可能需要有一个预发布的版本进行测试。
预发布分支是从Develop分支上面分出来的,预发布结束以后,必须合并进Develop和Master分支。它的命名,可以采用release-*的形式。
创建一个预发布分支:
git checkout -b release-1.2 develop
确认没有问题后,合并到master分支:
git checkout master
git merge --no-ff release-1.2
git tag -a 1.2
再合并到develop分支:
git checkout develop
git merge --no-ff release-1.2
最后,删除预发布分支:
git branch -d release-1.2
## 六、修补bug分支
最后一种是修补bug分支。软件正式发布以后,难免会出现bug。这时就需要创建一个分支,进行bug修补。
修补bug分支是从Master分支上面分出来的。修补结束以后,再合并进Master和Develop分支。它的命名,可以采用fixbug-*的形式。

创建一个修补bug分支:
git checkout -b fixbug-0.1 master
修补结束后,合并到master分支:
git checkout master
git merge --no-ff fixbug-0.1
git tag -a 0.1.1
再合并到develop分支:
git checkout develop
git merge --no-ff fixbug-0.1
最后,删除”修补bug分支”:
git branch -d fixbug-0.1
树形结构的数据库表Schema设计
16年09月06日
程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化。然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,因此是不能直接将Tree存入DBMS,设计合适的Schema及其对应的CRUD算法是实现关系型数据库中存储树形结构的关键。
理想中树形结构应该具备如下特征:数据存储冗余度小、直观性强;检索遍历过程简单高效;节点增删改查CRUD操作高效。依据Gijs Van Tulder写的《Storing Hierarchical Data in a Database》整理了一下,本文将介绍三种树形结构的Schema设计方案:
- The Adjacency List Model(“邻接列表模型”或“递归方法”)
- Route Path(路径法)
- Modified Preorder Tree Traversal(预排序遍历树算法,基于节点左右值编码的改进方案)
树模型实例
以食品作为演示数据,通过类别、颜色、品种进行分类,树结构如下:
Food
|---Fruit
| |---Red
| | +---Cherry
| +---Yellow
| +---Banana
|---Meat
|---Beef
+---Pork
The Adjacency List Model(“邻接列表模型”或“递归方法”)
这种模式我们经常用到,很多的教程和书中也介绍过。我们通过给每个节点增加一个属性 parentID 来表示这个节点的父节点从而将整个树状结构通过平面的表描述出来。这种方案的Tree表结构通常设计为:{ID,parentID},上述数据可以描述为如下图所示:
+----+--------+----------+
| ID | tName | parentID |
+----+--------+----------+
| 1 | Food | 0 |
| 2 | Fruit | 1 |
| 3 | Red | 2 |
| 4 | Yellow | 2 |
| 5 | Cherry | 3 |
| 6 | Banana | 4 |
| 7 | Meat | 1 |
| 8 | Beef | 7 |
| 9 | Pork | 7 |
+----+--------+----------+
parentID 对应 ID,parentID=0时表示其无父级
这种模式适用需要对树末端节点(叶子)进行增加、删除、移动的操作(删除、移动最好先行判断是否末端节点),也适用于对子树的移动。但读取某个节点的子孙节点数、同级节点、节点所在层级、节点到根节点的路径、删除子树将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。当然,这种方案并非没有用武之地,在树规模相对较小的情况下,我们可以借助于缓存机制来做优化,将树的信息载入内存进行处理,避免直接对数据库IO操作的性能开销,不过这也只能解决单纯对树本身的操作。
Route Path(路径法)
通过记录每个节点到根节点的路径的方法整个树状结构通过平面的表描述出来。这种方案的Tree表结构通常设计为:{ID,pathnode},上述数据可以描述为如下图所示:
+----+--------+-----------+
| ID | tName | pathNode |
+----+--------+-----------+
| 1 | Food | ,1, |
| 2 | Fruit | ,1,2, |
| 3 | Red | ,1,2,3, |
| 4 | Yellow | ,1,2,4, |
| 5 | Cherry | ,1,2,3,5, |
| 6 | Banana | ,1,2,4,6, |
| 7 | Meat | ,1,7, |
| 8 | Beef | ,1,7,8, |
| 9 | Pork | ,1,7,9, |
+----+--------+-----------+
pathNode 以“,”开始结束,方便Like查询
这种模式解决了第一种模式的不足,但有两点美中不足: * 增加节点时需要先获取到新节点的ID才能得到完整的路径 * 所有操作都是基于Like或者数组进行的
Modified Preorder Tree Traversal(预排序遍历树算法,基于节点左右值编码的改进方案)
在基于数据库的一般应用中,查询的需求总要大于删除和修改,我们希望尽量减少对数据库的查询次数,最好每个活动只有一个查询来提高程序的效率,现在让我们看看另外一种树结构的存储方法:
+----+--------+------+------+
| ID | tName | lft | rgt |
+----+--------+------+------+
| 1 | Food | 1 | 18 |
| 2 | Fruit | 2 | 11 |
| 3 | Red | 3 | 6 |
| 4 | Yellow | 7 | 10 |
| 5 | Cherry | 4 | 5 |
| 6 | Banana | 8 | 9 |
| 7 | Meat | 12 | 17 |
| 8 | Beef | 13 | 14 |
| 9 | Pork | 15 | 16 |
+----+--------+------+------+
如下图所示。当我们从根节点Food左侧开始,标记为1,并沿前序遍历的方向,依次在遍历的路径上标注数字,最后我们回到了根节点Food,并在右边写上了18。
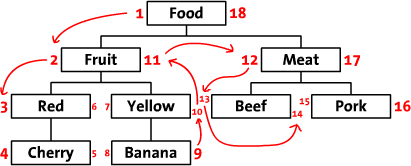
这种左右值编码的设计方案,在对树进行查询遍历时消除了递归,查询条件都是数字的比较,查询的效率不言而喻。但是左右值模式在插入、删除、移动节点或子树时代价较大,将会涉及到表中的多条数据改动。此种方案适合树不经常变动读取量大的场景中使用。
总结
上述三种方案结合再对表结构增加”tLevel”字段(节点层级),对树增删移后进行修复,在对树的需求场景中均能高效率应对。引用《倚天屠龙记》片段作为结尾:
张三丰这套武功由真武大帝座下龟蛇二将而触机创制,是以名之为“真武七截阵”。他当时苦思难解者,总觉顾得东边,西边便有漏洞,同时南边北边,均予敌人可乘之机,后来想到可命七弟于齐施,才破解了这个难题。只是这“真武七截阵”不能由一人施展,总不免遗憾,但转念想道:“这路武功倘若一人能使,岂非单是一人,便足匹敌当世六十四位第一流高手,这念头也未免过于荒诞狂妄了。”不禁哑然失笑。